const ( // Maximum number of key/value pairs a bucket can hold. bucketCntBits = 3 bucketCnt = 1 << bucketCntBits ) // A header for a Go map. type hmap struct { // Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go. // Make sure this stays in sync with the compiler's definition. count int// # live cells == size of map. Must be first (used by len() builtin) flags uint8 B uint8// log_2 of # of buckets (can hold up to loadFactor * 2^B items) noverflow uint16// approximate number of overflow buckets; see incrnoverflow for details hash0 uint32// hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0. oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing nevacuate uintptr// progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields }
// mapextra holds fields that are not present on all maps. type mapextra struct { // If both key and elem do not contain pointers and are inline, then we mark bucket // type as containing no pointers. This avoids scanning such maps. // However, bmap.overflow is a pointer. In order to keep overflow buckets // alive, we store pointers to all overflow buckets in hmap.extra.overflow and hmap.extra.oldoverflow. // overflow and oldoverflow are only used if key and elem do not contain pointers. // overflow contains overflow buckets for hmap.buckets. // oldoverflow contains overflow buckets for hmap.oldbuckets. // The indirection allows to store a pointer to the slice in hiter. overflow *[]*bmap oldoverflow *[]*bmap
// nextOverflow holds a pointer to a free overflow bucket. nextOverflow *bmap }
// A bucket for a Go map. type bmap struct { // tophash generally contains the top byte of the hash value // for each key in this bucket. If tophash[0] < minTopHash, // tophash[0] is a bucket evacuation state instead. tophash [bucketCnt]uint8 // Followed by bucketCnt keys and then bucketCnt elems. // NOTE: packing all the keys together and then all the elems together makes the // code a bit more complicated than alternating key/elem/key/elem/... but it allows // us to eliminate padding which would be needed for, e.g., map[int64]int8. // Followed by an overflow pointer. }
这个就是 Go map 底层结构的部分源码了,业务代码中的每一个 map 底层对应的就是一个 hmap
for i := uintptr(0); i < bucketCnt; i++ { if b.tophash[i] != top { if b.tophash[i] == emptyRest { break bucketloop } continue } k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) if t.indirectkey() { k = *((*unsafe.Pointer)(k)) } if t.key.equal(key, k) { e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize)) if t.indirectelem() { e = *((*unsafe.Pointer)(e)) } return e } }
// The current bucket and all the overflow buckets connected to it are full, allocate a new one. newb := h.newoverflow(t, b) inserti = &newb.tophash[0] insertk = add(unsafe.Pointer(newb), dataOffset) elem = add(insertk, bucketCnt*uintptr(t.keysize))
// If we hit the max load factor or we have too many overflow buckets, // and we're not already in the middle of growing, start growing. if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) { hashGrow(t, h) goto again // Growing the table invalidates everything, so try again }
翻倍扩容
overLoadFactor 指示数据是否太多,需要翻倍扩容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
const ( // Maximum average load of a bucket that triggers growth is 6.5. // Represent as loadFactorNum/loadFactorDen, to allow integer math. loadFactorNum = 13 loadFactorDen = 2 ) // overLoadFactor reports whether count items placed in 1<<B buckets is over loadFactor. funcoverLoadFactor(count int, B uint8)bool { return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen) } // bucketShift returns 1<<b, optimized for code generation. funcbucketShift(b uint8)uintptr { // Masking the shift amount allows overflow checks to be elided. returnuintptr(1) << (b & (goarch.PtrSize*8 - 1)) }
// tooManyOverflowBuckets reports whether noverflow buckets is too many for a map with 1<<B buckets. // Note that most of these overflow buckets must be in sparse use; // if use was dense, then we'd have already triggered regular map growth. functooManyOverflowBuckets(noverflow uint16, B uint8)bool { // If the threshold is too low, we do extraneous work. // If the threshold is too high, maps that grow and shrink can hold on to lots of unused memory. // "too many" means (approximately) as many overflow buckets as regular buckets. // See incrnoverflow for more details. if B > 15 { B = 15 } // The compiler doesn't see here that B < 16; mask B to generate shorter shift code. return noverflow >= uint16(1)<<(B&15) }
// incrnoverflow increments h.noverflow. // noverflow counts the number of overflow buckets. // This is used to trigger same-size map growth. // See also tooManyOverflowBuckets. // To keep hmap small, noverflow is a uint16. // When there are few buckets, noverflow is an exact count. // When there are many buckets, noverflow is an approximate count. func(h *hmap) incrnoverflow() { // We trigger same-size map growth if there are // as many overflow buckets as buckets. // We need to be able to count to 1<<h.B. if h.B < 16 { h.noverflow++ return } // Increment with probability 1/(1<<(h.B-15)). // When we reach 1<<15 - 1, we will have approximately // as many overflow buckets as buckets. mask := uint32(1)<<(h.B-15) - 1 // Example: if h.B == 18, then mask == 7, // and fastrand & 7 == 0 with probability 1/8. if fastrand()&mask == 0 { h.noverflow++ } }
B 小于 16 时,noverflow 是确切值,大于等于 16 时就是通过随机数按概率控制每次是否自增 1,为啥要搞这么麻烦呢?
funchashGrow(t *maptype, h *hmap) { // If we've hit the load factor, get bigger. // Otherwise, there are too many overflow buckets, // so keep the same number of buckets and "grow" laterally. bigger := uint8(1) if !overLoadFactor(h.count+1, h.B) { bigger = 0 h.flags |= sameSizeGrow } oldbuckets := h.buckets newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
funcgrowWork(t *maptype, h *hmap, bucket uintptr) { // make sure we evacuate the oldbucket corresponding // to the bucket we're about to use evacuate(t, h, bucket&h.oldbucketmask())
// evacuate one more oldbucket to make progress on growing if h.growing() { evacuate(t, h, h.nevacuate) } }
// evacDst is an evacuation destination. type evacDst struct { b *bmap // current destination bucket i int// key/elem index into b k unsafe.Pointer // pointer to current key storage e unsafe.Pointer // pointer to current elem storage }
funcevacuate(t *maptype, h *hmap, oldbucket uintptr) { b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))) newbit := h.noldbuckets() if !evacuated(b) { // TODO: reuse overflow buckets instead of using new ones, if there // is no iterator using the old buckets. (If !oldIterator.)
// xy contains the x and y (low and high) evacuation destinations. var xy [2]evacDst x := &xy[0] x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize))) x.k = add(unsafe.Pointer(x.b), dataOffset) x.e = add(x.k, bucketCnt*uintptr(t.keysize))
if !h.sameSizeGrow() { // Only calculate y pointers if we're growing bigger. // Otherwise GC can see bad pointers. y := &xy[1] y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize))) y.k = add(unsafe.Pointer(y.b), dataOffset) y.e = add(y.k, bucketCnt*uintptr(t.keysize)) }
for ; b != nil; b = b.overflow(t) { k := add(unsafe.Pointer(b), dataOffset) e := add(k, bucketCnt*uintptr(t.keysize)) for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) { top := b.tophash[i] if isEmpty(top) { b.tophash[i] = evacuatedEmpty continue } if top < minTopHash { throw("bad map state") } k2 := k if t.indirectkey() { k2 = *((*unsafe.Pointer)(k2)) } var useY uint8 if !h.sameSizeGrow() { // Compute hash to make our evacuation decision (whether we need // to send this key/elem to bucket x or bucket y). hash := t.hasher(k2, uintptr(h.hash0)) if h.flags&iterator != 0 && !t.reflexivekey() && !t.key.equal(k2, k2) { // If key != key (NaNs), then the hash could be (and probably // will be) entirely different from the old hash. Moreover, // it isn't reproducible. Reproducibility is required in the // presence of iterators, as our evacuation decision must // match whatever decision the iterator made. // Fortunately, we have the freedom to send these keys either // way. Also, tophash is meaningless for these kinds of keys. // We let the low bit of tophash drive the evacuation decision. // We recompute a new random tophash for the next level so // these keys will get evenly distributed across all buckets // after multiple grows. useY = top & 1 top = tophash(hash) } else { if hash&newbit != 0 { useY = 1 } } }
if dst.i == bucketCnt { dst.b = h.newoverflow(t, dst.b) dst.i = 0 dst.k = add(unsafe.Pointer(dst.b), dataOffset) dst.e = add(dst.k, bucketCnt*uintptr(t.keysize)) } dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i as an optimization, to avoid a bounds check if t.indirectkey() { *(*unsafe.Pointer)(dst.k) = k2 // copy pointer } else { typedmemmove(t.key, dst.k, k) // copy elem } if t.indirectelem() { *(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e) } else { typedmemmove(t.elem, dst.e, e) } dst.i++ // These updates might push these pointers past the end of the // key or elem arrays. That's ok, as we have the overflow pointer // at the end of the bucket to protect against pointing past the // end of the bucket. dst.k = add(dst.k, uintptr(t.keysize)) dst.e = add(dst.e, uintptr(t.elemsize)) } } // Unlink the overflow buckets & clear key/elem to help GC. if h.flags&oldIterator == 0 && t.bucket.ptrdata != 0 { b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)) // Preserve b.tophash because the evacuation // state is maintained there. ptr := add(b, dataOffset) n := uintptr(t.bucketsize) - dataOffset memclrHasPointers(ptr, n) } }
if oldbucket == h.nevacuate { advanceEvacuationMark(h, t, newbit) } }
funcadvanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) { h.nevacuate++ // Experiments suggest that 1024 is overkill by at least an order of magnitude. // Put it in there as a safeguard anyway, to ensure O(1) behavior. stop := h.nevacuate + 1024 if stop > newbit { stop = newbit } for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) { h.nevacuate++ } if h.nevacuate == newbit { // newbit == # of oldbuckets // Growing is all done. Free old main bucket array. h.oldbuckets = nil // Can discard old overflow buckets as well. // If they are still referenced by an iterator, // then the iterator holds a pointers to the slice. if h.extra != nil { h.extra.oldoverflow = nil } h.flags &^= sameSizeGrow } }
好了 Go map 源码暂时就分析到这了,还有 makemap 和遍历过程没分析,有兴趣的话自己看源码去吧
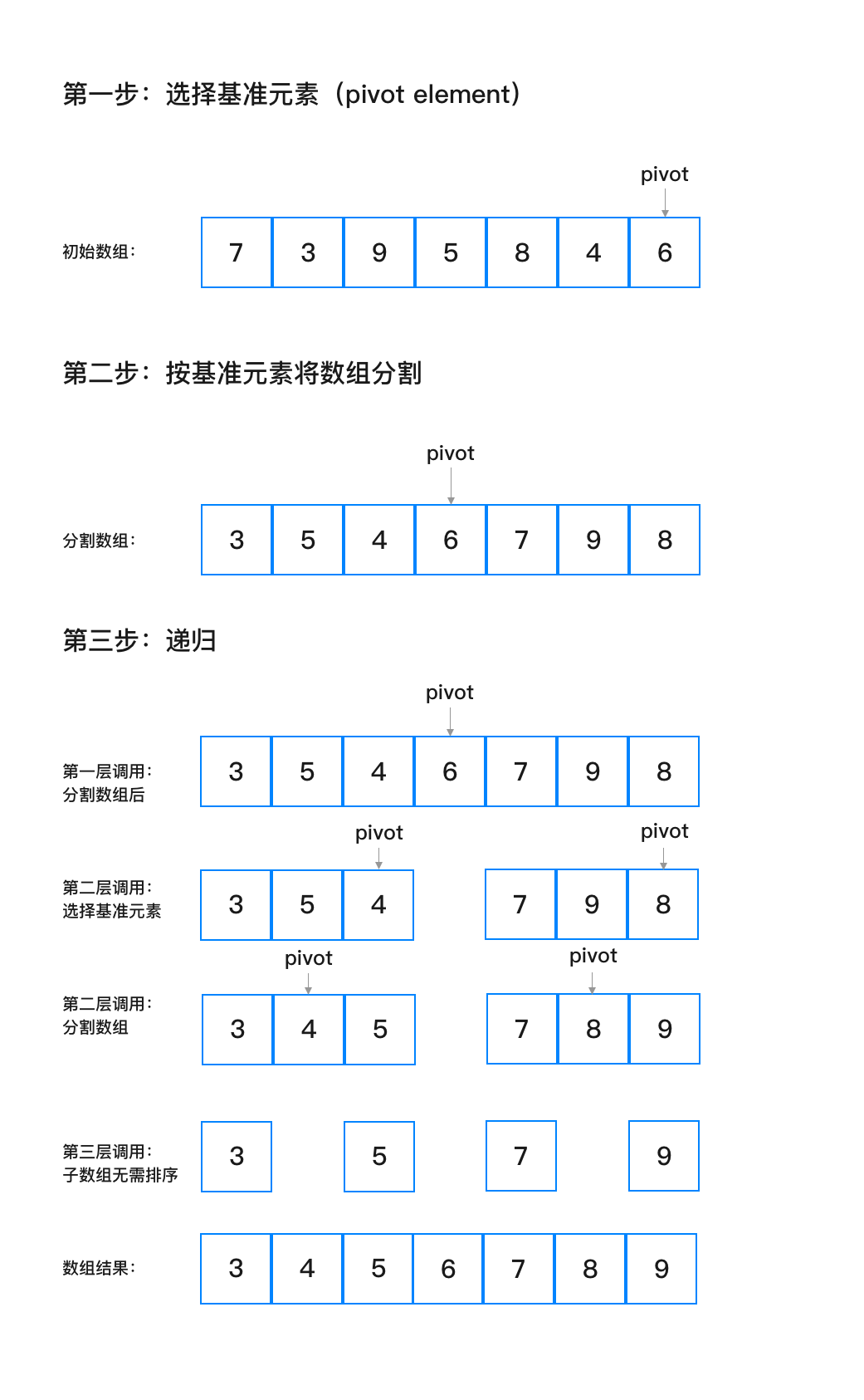
voidEXCHANGE(int *left, int *right) { if (left == right) return; *left ^= *right; *right ^= *left; *left ^= *right; }
intPARTITION(int A[], int left, int right) { int pivotValue = A[right]; int pivotDest = left; for (int i = left; i < right; i++) { if (A[i] <= pivotValue) { EXCHANGE(&A[pivotDest], &A[i]); pivotDest++; } } EXCHANGE(&A[pivotDest], &A[right]); return pivotDest; }
voidQUICKSORT(int A[], int left, int right) { if (left < right) { int pivot = PARTITION(A, left, right); QUICKSORT(A, left, pivot - 1); QUICKSORT(A, pivot + 1, right); } }
intmain(int argc, charconst *argv[]) { int A[] = {7, 3, 9, 5, 8, 4, 2}; QUICKSORT(A, 0, 7); for (int i = 0; i <= 7; i++) { printf("%d ", A[i]); } printf("\n"); return0; }
所有nginx的配置文件都在**/etc/nginx目录下,cd到这个目录。本次教程要添加的配置文件会放在其中一个名为sites-enabled目录下,cd到该目录里,你会发现有个default文件在里面,就是这个文件使你看见“welcome to nginx”。touch一个test**在该目录下并用你喜欢的编辑器打开